Redleaf 2.5: Why Chat Doesn't Scale for Deep Research
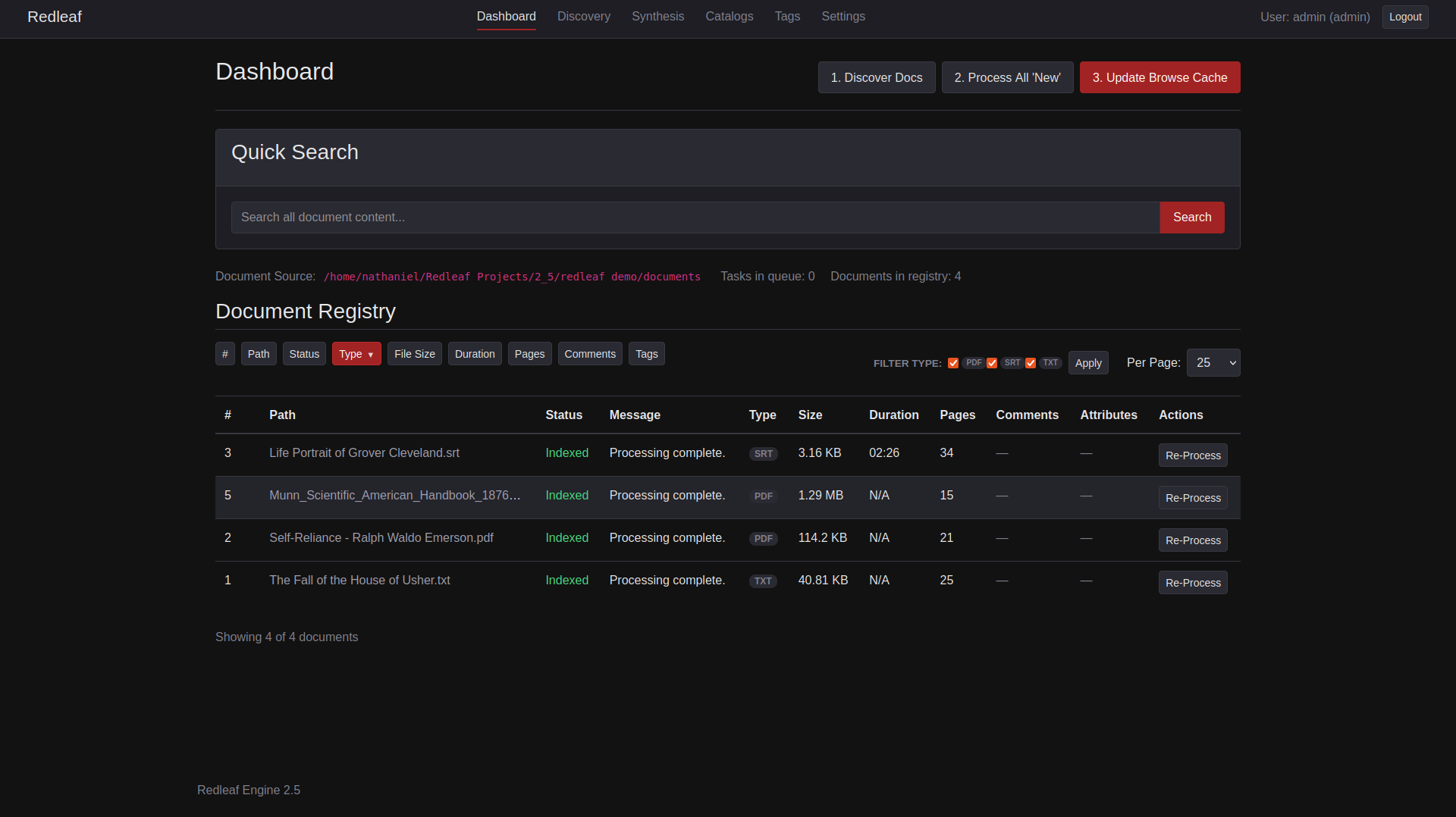
Redleaf Engine 2.5’s updated dashboard
Redleaf was originally built to solve a human problem. In early 2025, LLMs were unreliable for deep research: feed them a long document, and they would lose the thread halfway through. So, I built Redleaf to help people do RAG properly—extract entities, map relationships, and navigate information as a living structure instead of a wall of text.
Then, something changed.
As open-weight models improved, they stopped feeling like simple token generators and started behaving more like agents. In that shift, something unexpected happened.
It was not just a tool for humans. It was infrastructure for AI.
The Interface Breaks First
The first instinct was obvious: bolt an LLM onto the system.
It worked, but it immediately exposed the real problem.
Chat does not scale.
A single text box collapses multi-step investigation, branching paths, and parallel threads into one flat stream. The more capable the model becomes, the more the interface becomes the bottleneck.
My background in visual effects offered a different model. Tools like Nuke and Fusion do not hide complexity; they expose it through nodes. Every operation is explicit. Data flows are visible. You can trace exactly how something was produced.
That philosophy maps almost perfectly to how powerful AI systems should work—not as a conversation, but as a graph.
This realization didn’t just lead to a UI idea; it led to a second system entirely.
That system became Node Leaf.
Node Leaf emerged directly from Redleaf 2.5’s development. It has evolved rapidly alongside it, driven by a simple obsession: building toolchains that let users and agents operate at higher levels of structure and intent.
Node Leaf is the visual layer.
Redleaf is the engine beneath it.
Together, they form a single system for navigating complexity through structure rather than text.
But to be clear on the roadmap: Node Leaf and autonomous agents are not here to replace the human researcher. They are synthetic companions.
Humans will always have access to the exact same tools the AI does. The core problem in knowledge work—and why AI took off in the first place—is an I/O bottleneck. We are bottlenecked by a pointing device and a screen, inputting queries one keystroke at a time.
We have made this as efficient as possible, and with Redleaf, I believe I’ve closed that gap even more. Redleaf’s UI exists to give humans the same high-speed traversal capabilities the agents use:
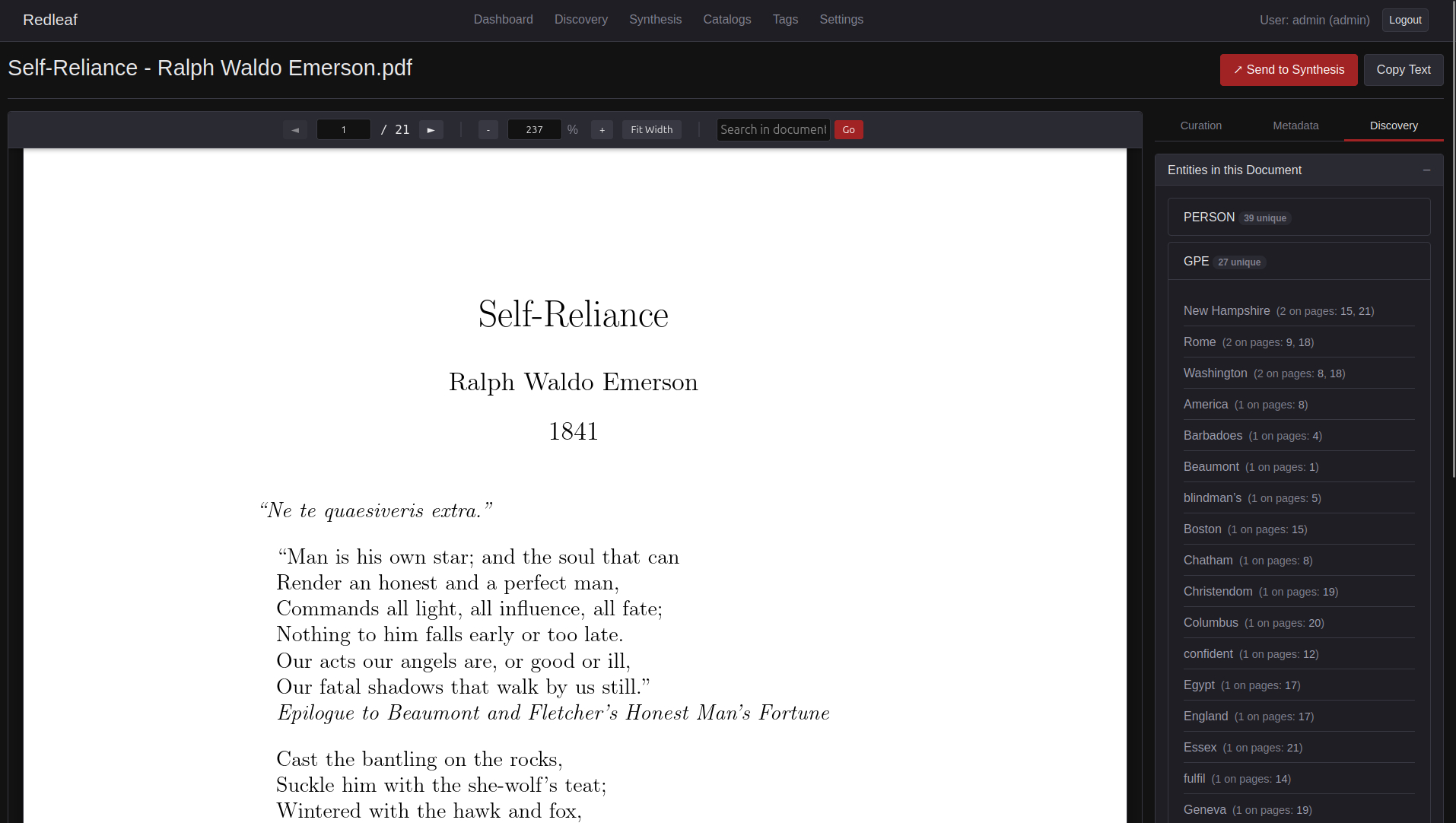
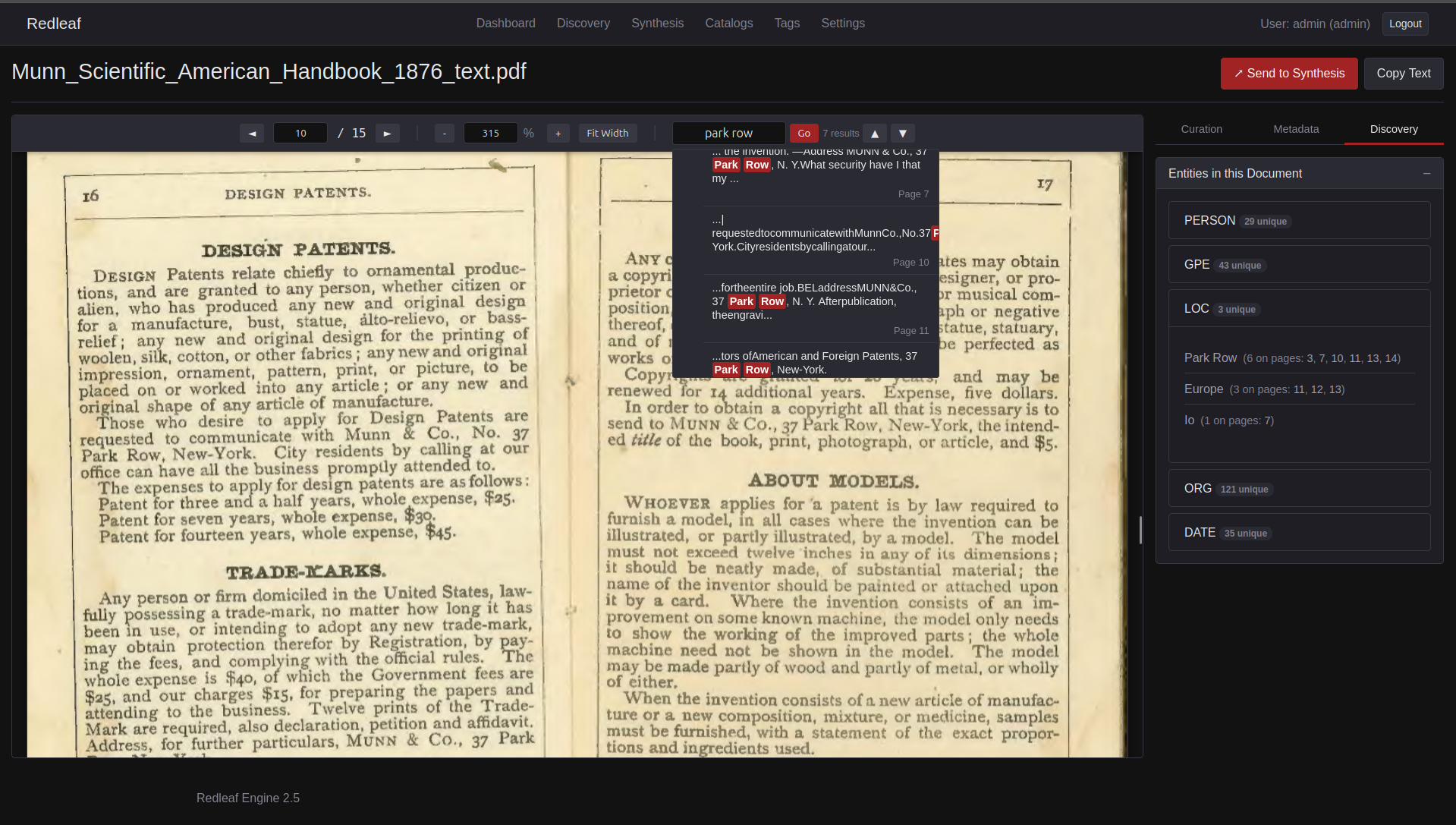
- Instant Relevance: Instead of reading linearly, spaCy NLP automatically detects and surfaces the most critical entities in a document.
- Click-and-Go Navigation: Automatic bibliographies are generated alongside each document, allowing you to instantly click and go exactly to where entities are mentioned.
- Intersectional Filtering: Advanced search allows you to build a set of conditions to filter down documents, finding highly specific intersections of pure signal.
Humans and agents, navigating the same graph, using the exact same tools.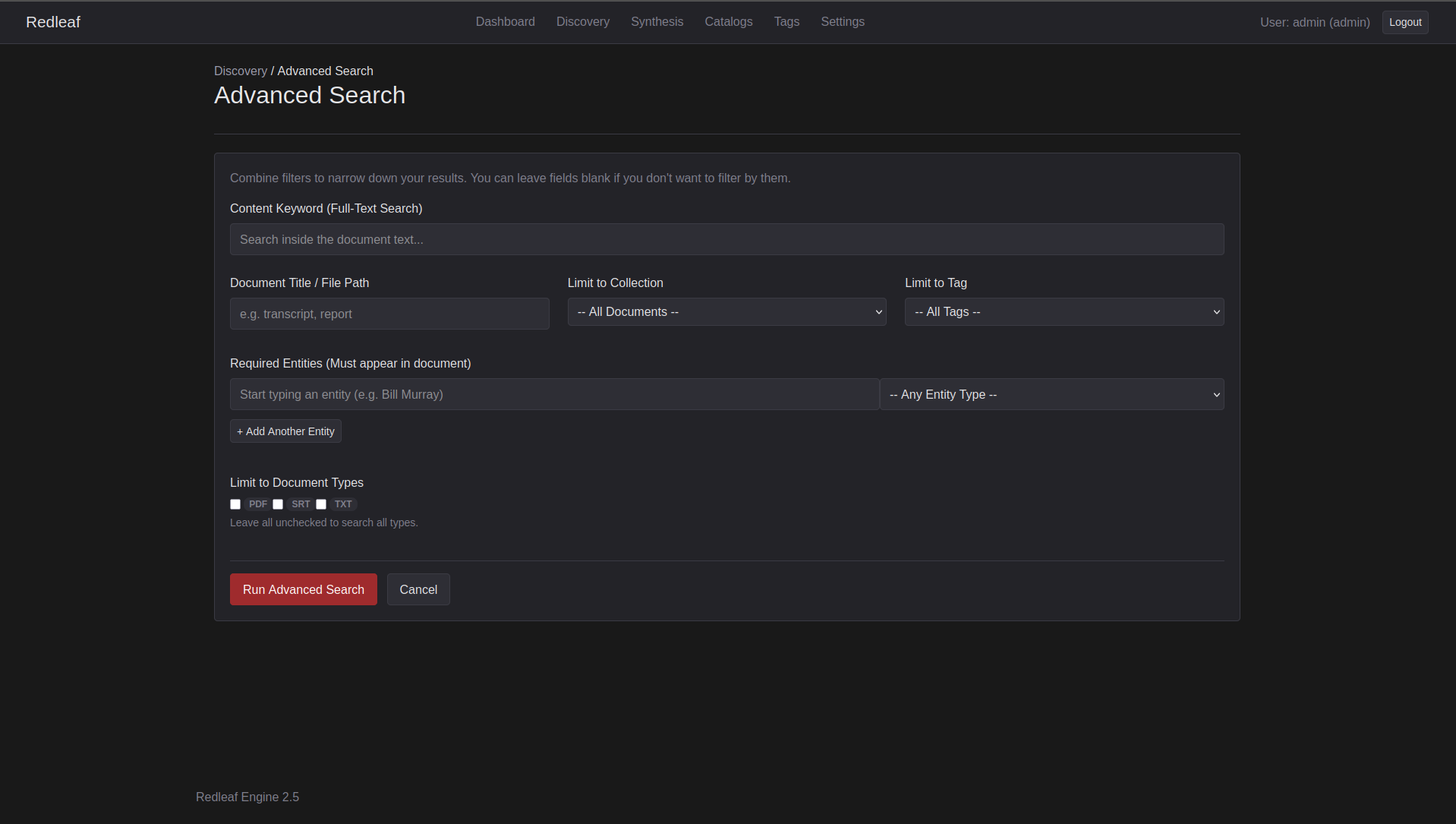
Redleaf’s new advanced search
Redleaf 2.5
Redleaf 2.5 is not a feature update; it is a role change.
What began as a document explorer is now a backend system designed to be used by other systems. The UI remains, but it is no longer the center.
The engine is the center. The GUI remains a first-class experience for the user.
Built for Agents, Not Prompts
Most RAG systems follow a simple loop: input → search → output.
Redleaf 2.5 breaks that loop open. The retrieval engine is now fully exposed. Agents do not just ask questions; they construct precise, layered queries across the knowledge graph.
A single API call can combine full-text search, entity filters, and file constraints:
{
"q": "economics",
"entities": [
{"text": "Soviet Union", "label": "GPE"}
],
"file_types": ["PDF", "TXT"],
"limit": 5
}
Redleaf handles the heavy lifting—graph traversal, entity intersection, and FTS5 querying—so the model can focus purely on interpretation, comparison, and synthesis.
This is what powers Node Leaf’s “Research Party”: coordinated agents that search, cross-reference, challenge assumptions, and produce grounded analysis.
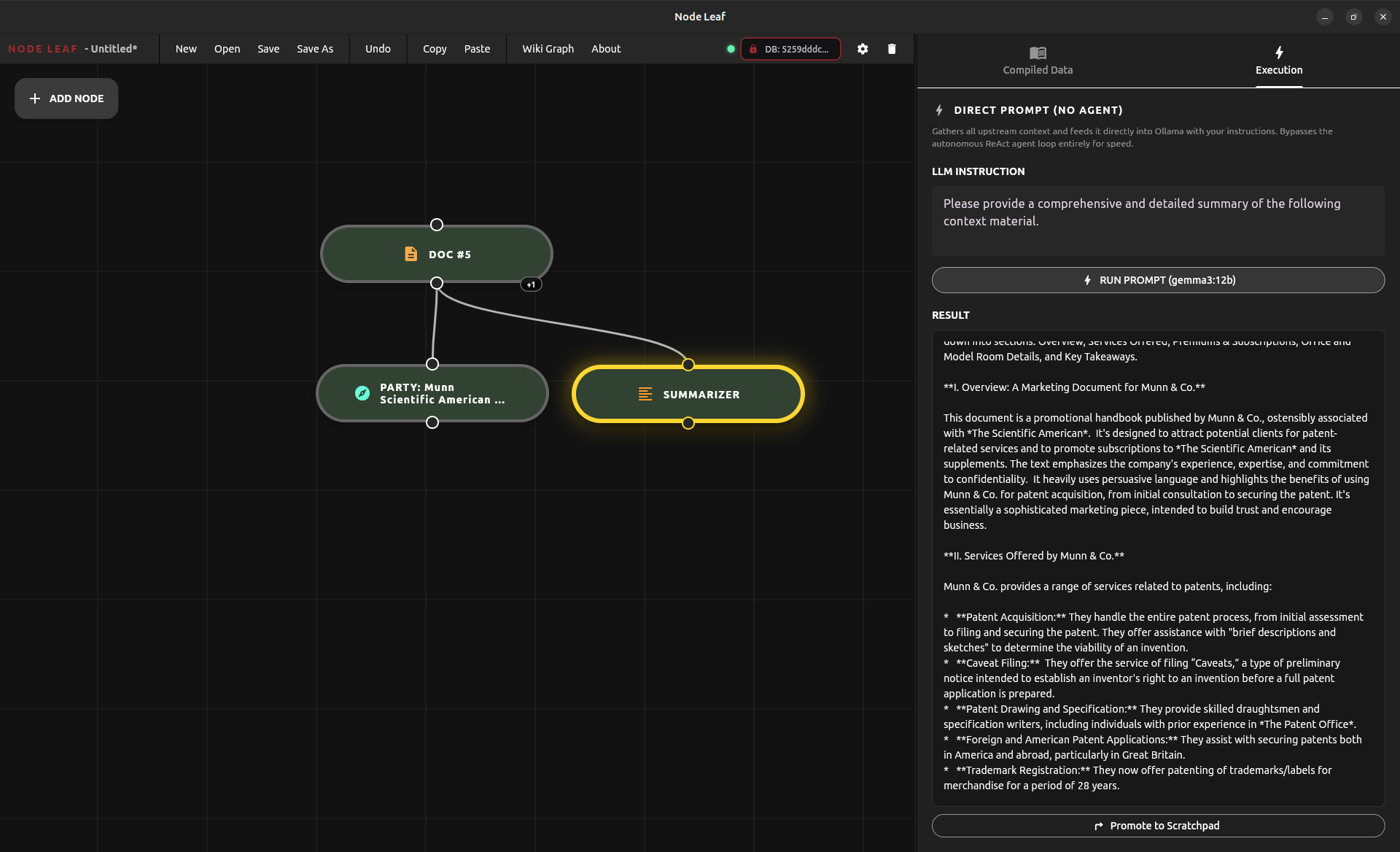
Node Leaf Summarizer node writes a broad overview
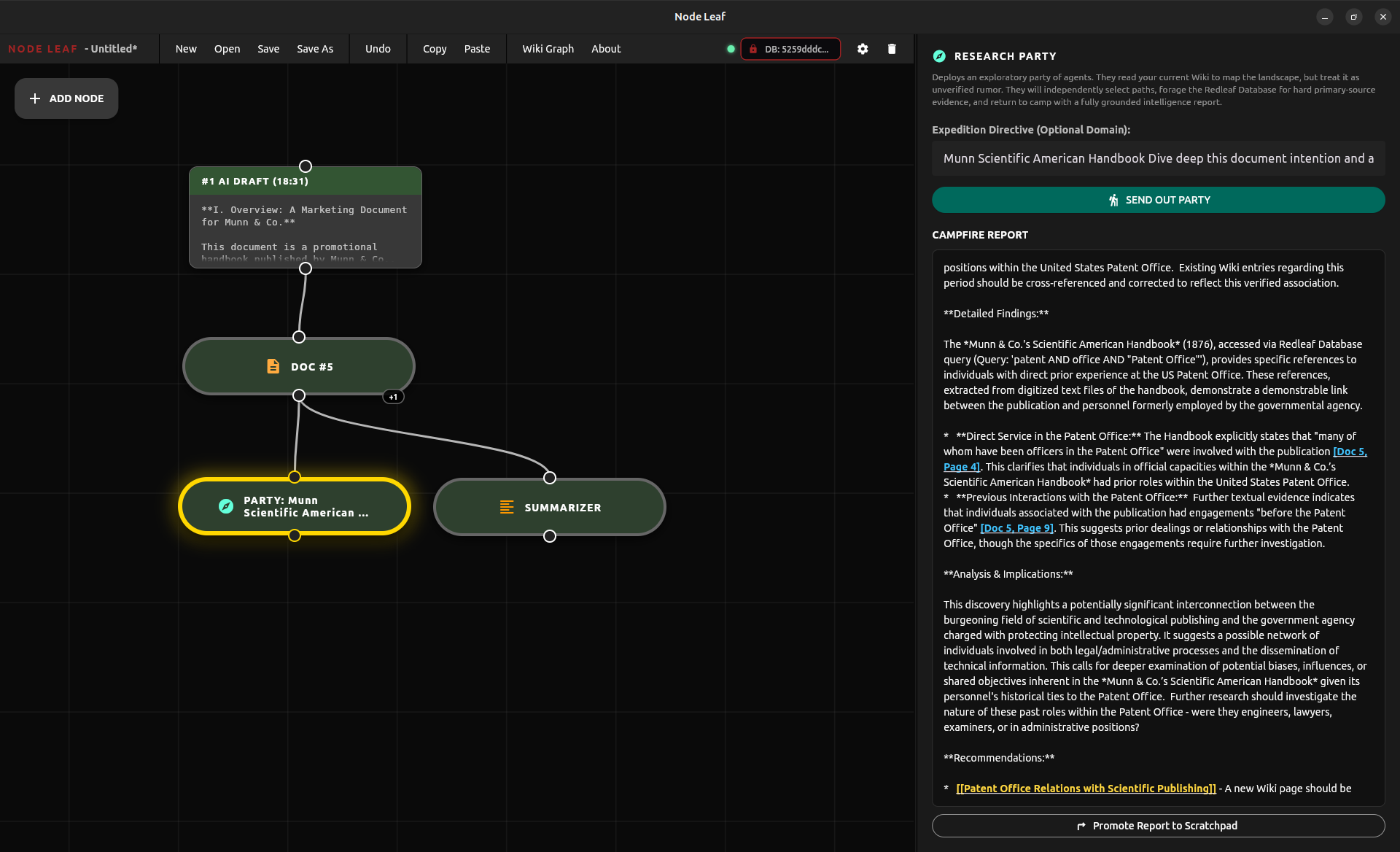
Node Leaf Research party utilizing the summary node output to explore the document
Node Leaf agents utilizing Redleaf 2.5 APIs to forage for primary source data
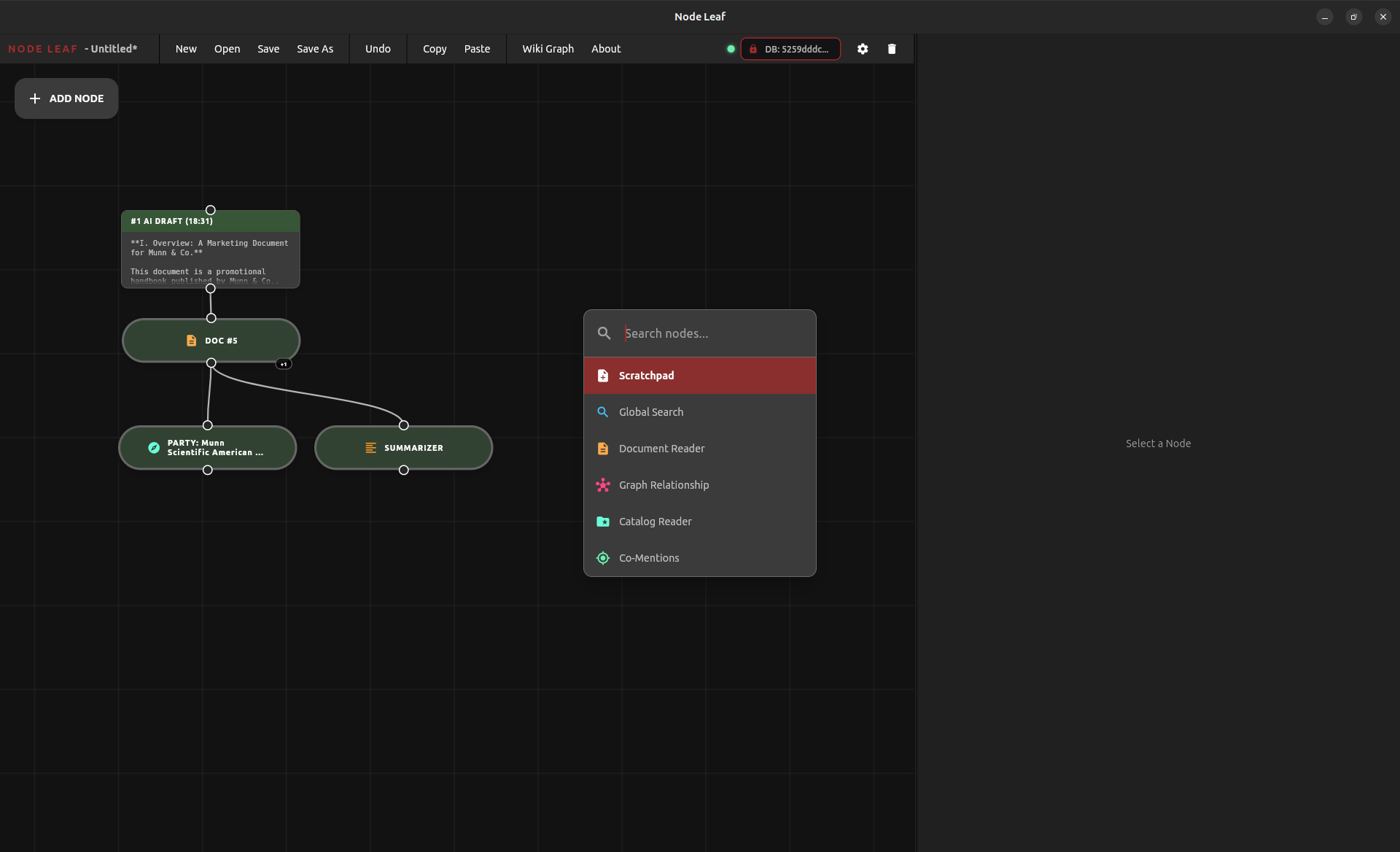
Node Leaf’s updated tab search lets you dynamically surface nodes instantly without digging through long menus
High-Throughput Ingestion
Scaling the system exposed a different kind of problem.
At scale, ingestion becomes the real bottleneck.
Redleaf 2.5 introduces a dual-database architecture.
- DuckDB handles the heavy ETL work: raw text extraction, spaCy NLP relationship mapping, and embedding generation.
- SQLite serves as the fast, stable query layer for agents and the frontend.
Think of it as a refinery feeding a distribution network: raw data in, structured intelligence out. Heavy processing happens once; fast access happens everywhere.
Letting Data Stay Where It Is
Real knowledge work rarely lives in one tidy folder. Archives span external drives, network shares, and multiple machines.
Redleaf 2.5 introduces Virtual Folders (.rlink). External sources can be linked directly into the knowledge graph without duplication.
If a drive disappears, nothing breaks. Files are simply marked as Missing. Plug it back in, and all relationships, notes, and embeddings reconnect instantly.
The system adapts to your storage reality instead of fighting it.
Data stays where it belongs.
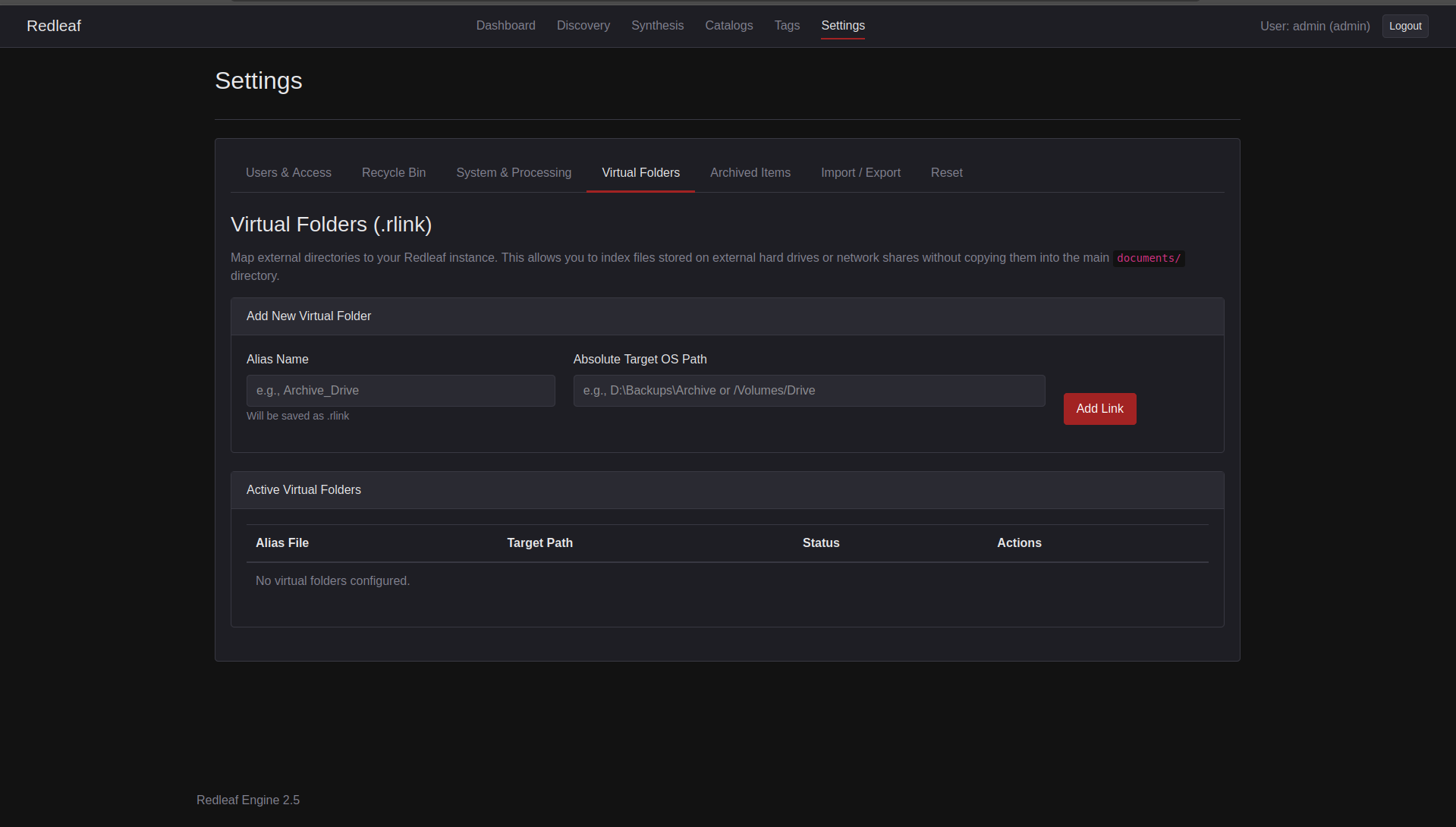
Redleaf 2.5’s new Virtual Folder Manager
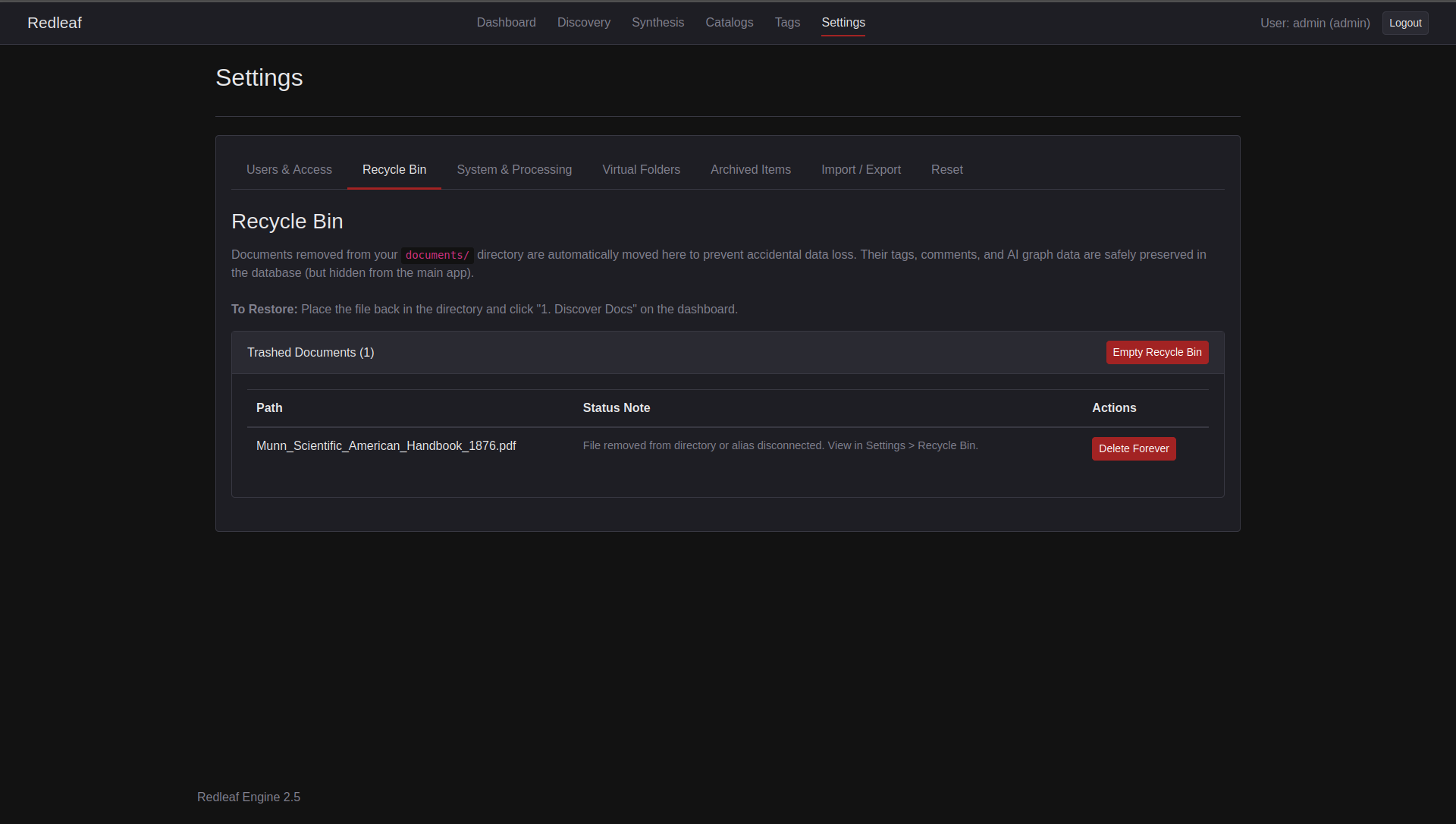
If Redleaf can't find a discovered file, it moves it to the new recycle bin for recovery or removal
A Strategic Pivot
Earlier plans focused on improved document rendering and custom PDF viewers. That work still has value, but it is no longer the priority.
Enabling autonomous exploration and reasoning had to come first.
What Redleaf Becomes
Redleaf 2.5 is no longer just something you use.
It becomes a foundation.
A system that ingests, structures, and serves knowledge fast enough for autonomous agents to think on top of it. The human interface remains rich and exploratory, but alongside it, a new capability has emerged.
Agents moving through your data, surfacing unexpected connections, testing ideas, and returning insights you would not have assembled alone.
It stops feeling like search.
It starts feeling like discovery in motion.
Redleaf 2.5 is available now: https://github.com/nathanfx330/redleaf
Node Leaf 1.5: https://github.com/nathanfx330/node-leaf